

Let’s see how we can create and run a simple DataStage flow using DataStage as a Service on IBM Cloud. Later we can extend simple flows into complex data transformation pipelines. Assuming you already have DataStage provisioned and project created as explained here.
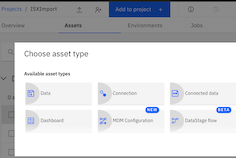
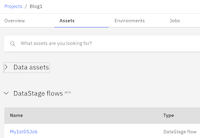
Step 1: Go to the project and click on Add to Project. It should bring different asset types. Choose DataStage flow from available types. Now give a name to DataStage flow say My1stDSJob and provide some description. Click on Create. Now you should see DataStage canvas where can drag and drop different connectors and create the flow
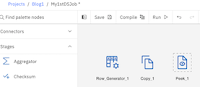
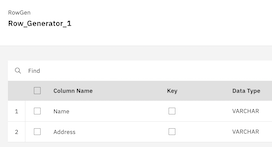
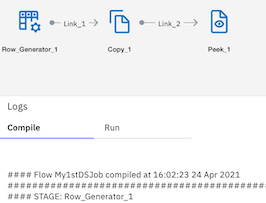
Step 2: Let’s create a simple flow row-gen to generate data, copy stage and peek to see the outcome. From the pallet node, click on stages and drag and drop required stages to the canvas and link them appropriately. Define different columns say name and address by clicking output column of row gen and copy stage and save them. Now hit the save followed by compile button. Flow is created and compiled and can be seen under datastage flow assets.
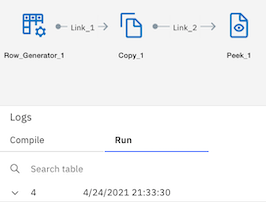
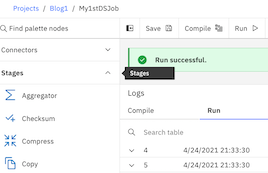
Step 3: Hit the run icon to execute the created flow on DataStage canvas. Behind the scene, it will go to its designated runtime environent and execute the flow. After few seconds flow will be executed successfully and you can see the logs and the jobs dashboard. It will also provide a summary of the run for consumption in the future.
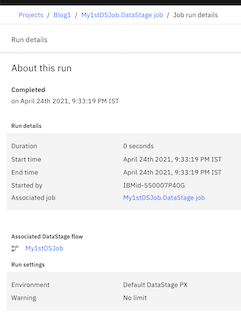
 Step 4: Review the results and download the logs if required for further analysis.
Step 4: Review the results and download the logs if required for further analysis.
Now you are all set to create complex DataStage flows on IBM Cloud or even can bring existing flow in ISX format and import it. More on it next time.
-Ritesh
